Class 3: More OOP and Exception Handling#
Object Oriented Programming: Part 2#
Inheritance#

One of the most interesting aspects or features of object-oriented programming is inheritance. Inheritance is a specific type of relation between the objects we create that signifies that a “child” object inherits from its “parent”. In other words, the child object “is a” parent object. Our examples so far were of “real-life” objects, and so to continue this line we’d perhaps wish to create a class of a Person, which would be the parent class, and a child class of a Student. In this examples it’s clear why a Student is a Person, so the inheritance holds. All Person instances have a name, age, gender, etc., but only Student instances have an associated school and a final grade. This means that the Student will have all attributes associated with all Persons (name, age, gender), and they’ll also have a school and a grade, the is referred to as “inheritance”.
Say that we have some computational pipeline, that reads some data, preprocesses it (denoising, filtering, changing its dimensions), then it computes some measurement of that dataset (number of cells in the image, mean calcium activity, min-max of electrical activity) and finally it writes it to disk. Let’s focus on the first step of this pipeline - reading in the data.
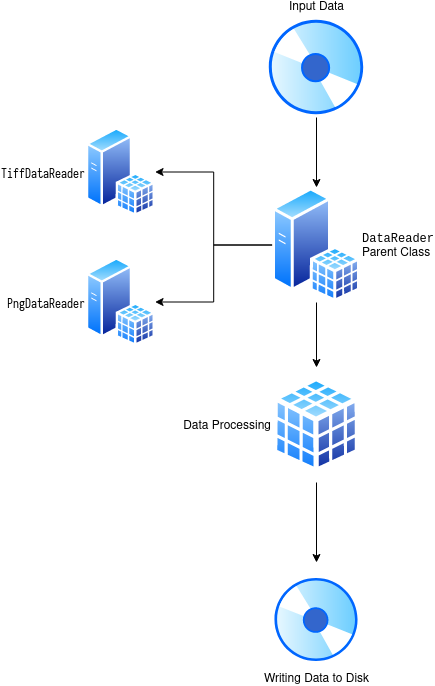
Our approach will be the following: we will build a parent class called DataReader, and its child classes will know how to read in specific data formats only. In the graph above we’ll have two child implementations: one that can read .tif images, and one for .png. This will allow us to “plug in” different classes into our pipeline, depending on the input, and the downstream functions won’t see a difference.
from pathlib import Path
class DataReader:
"""
Base class for DataReader objects.
This class provides an "interface" for subclasses to implement which
conforms with the larger data processing pipeline of this project.
"""
def __init__(self, path: Path):
"""
Initialize a new instance.
Parameters
----------
path : Path
Input data path
"""
self.path = Path(path)
self.data = None
def read(self):
"""Reads data into disk and returns it. Should populate self.data."""
raise NotImplementedError
def summarize(self):
"""Returns an informative summary of the data."""
raise NotImplementedError
This parent class could be initialized with:
path = Path("/some/path.tiff")
data_reader = DataReader(path)
and no harm will be done, but in practice there’s little one can achieve with this class. Any class that inherits from this base class has all methods the parent class has, but currently all they do is simply raise an error (an exception) called NotImplementedError.
path = 'a.png'
data_reader = DataReader(path)
data_reader.read()
---------------------------------------------------------------------------
NotImplementedError Traceback (most recent call last)
Cell In[3], line 3
1 path = 'a.png'
2 data_reader = DataReader(path)
----> 3 data_reader.read()
Cell In[1], line 25, in DataReader.read(self)
23 def read(self):
24 """Reads data into disk and returns it. Should populate self.data."""
---> 25 raise NotImplementedError
NotImplementedError:
This NotImplementedError tells the users of this class that they’ll have to implement this method when they derive the child class if they wish to have anything done with this interface. Let’s see how we write a child class:
from pathlib import Path
import tifffile
class TifDataReader(DataReader):
"""
A DataReader subclass for reading *.tif* files.
"""
def read(self):
"""
Reads a *.tif* image to self.data and returns it as well.
"""
self.data = tifffile.imread(file)
return self.data
def summarize(self) -> float:
"""
Returns the mean of the data.
Returns
-------
float
Data mean
"""
return self.data.mean()
def calculate_tif_thing(self, data):
"""Calcualtes some measurement from a *.tif* file."""
pass
Inheritance happens when you pass some class using the braces of the class definition. This tells Python to transfer attributes and methods from the parent to this child.
Note how on one hand we didn’t have to rewrite the __init__() method to define the instance initialization parameters, and on the other hand we had no problem creating a new calculate_tif_thing() method to provide some .tif-specific functionality. In between we have the read() and summarize() methods, which where implemented by overriding the base class’s.
Let’s consider how one could use this class:
path = 'a.tif'
tif_data_reader = TifDataReader(path)
tif_data_reader.path
PosixPath('a.tif')
tif_data_reader has the .read() and .summarize() method ready to use. We won’t read an actual .tif file but you can see that nothing is really special about this class and instance. Inheritance in this case helped us give a tag to this class, signaling to its users that it’s “special” and should be used in some specific contexts.
Note
Sometimes we wish to call the parent class’s method, particularly when overriding that same method in the subclass and wanting to continue any base class logic, or when modifying the instance initialization logic.
This is easily done by using the built-in super() function, e.g.:
class ChildClass(ParentClass):
def overridden_method(self, arg_1, arg_2):
base_class_result = super().overridden_method(arg_1, arg_2)
return self.another_calculation(base_class_result)
Inheritance - Why and When#
Inheritance can facilitate code re-use and simpler, clearer mental models of the problem at hand. In the example above, we generated very clear and concise classes that do one thing, and do it well. People reading this code, including us in three months, will understand everything about it without any hassle.
A possible issue with inheritance is readability - finding the methods that are associated with the base class can be cumbersome when we start working with tens of attributes and multiple methods. This is why usually people try to avoid more than a single layer of inheritance.
Exercise: The Person Base Class
You have decided to write a program that will manage the entirety of your lab’s data and you’re considering creating a Person class that will be the base class for the Researcher and the Participant classes. Note that:
The shared attributes are:
first_name,last_name,id_number,sex, anddate_of_birth.Researchers also have
titleandpositionattributes.Participants also have
weightanddominant_handattributes.Both classes need a
get_full_name()method to return the full name, but theResearcherclass should include thetitleas a prefix if it is specified.The
Participantclass should also have aread_text()method that reads a file that is expected to be found under data/<id_number>.txt and returns its content.
Solution
from datetime import datetime
from pathlib import Path
class Person:
"""
Base class representing people.
"""
def __init__(self, **kwargs):
"""
Extracts person attributes from the provided keyword arguments.
"""
self.first_name: str = kwargs.get("first_name", "")
self.last_name: str = kwargs.get("last_name", "")
self.id_number: str = kwargs.get("id_number", "")
self.sex: str = kwargs.get("sex", "")
self.date_of_birth: datetime.date = kwargs.get("date_of_birth")
def get_full_name(self) -> str:
"""
Returns the full name of the person in the format of "first last".
Returns
-------
str
Full name
"""
return f"{self.first_name} {self.last_name}"
class Researcher(Person):
"""
Represents a researcher in the lab.
"""
def __init__(self, **kwargs):
"""
Extract researcher attributes from the provided keyword arguments.
"""
super().__init__(**kwargs)
self.title: str = kwargs.get("title", "")
self.position: str = kwargs.get("position", "")
def get_full_name(self) -> str:
"""
Returns the full name of the researcher, including their title.
Returns
-------
str
Researcher name and title
"""
full_name = super().get_full_name()
# Introducting Python's ternary expressions:
return f"{self.title} {full_name}" if self.title else full_name
def Participant(Person):
"""
Represents a participant in some experiment.
"""
TEXT_PATH_TEMPLATE: str = "data/{id_number}.txt"
def __init__(self, **kwargs):
super().__init__(**kwargs)
self.weight: float = kwargs.get("weight")
self.dominant_hand: str = kwargs.get("dominant_hand", "")
def read_text(self) -> str:
"""
Reads the participant's textual data from a predefined location.
Returns
-------
str
Participants textual data
"""
path = self.TEXT_PATH_TEMPLATE.format(id_number=self.id_number)
with open(path, "r") as text_file:
return text_file.read()
Object-oriented design requires you to think about the code you’re about to write - how to model each object, how to deal with the interfaces between them, how to verify the types of each input, etc.
Classes are tremendously powerful, but require a great deal of experience in order to be used wisely. Until we can envision complete entity structures in our mind and account for all the details of their implementation and interactions, we do our best, we learn from it, and then we do better. Rewriting large parts of an application you designed is expected, it is a natural and important part of software design (and a luxury other engineers rarely have).
The term used to describe rewriting parts of some code in a way that preserves its original function but somehow improves it (performance, readability, documentation) is refactoring, and it is absolutely crucial.
Errors and Exceptions#
A very debated feature of Python (and other scripting languages) is its fear of failing. Python tries to coerce unknown commands into something familiar that it can work with. For example, addition of bools and other types is fully supported, since bool types are treated as 0 (for False) and 1 (for True).
True - 1.0
0.0
False + 10
10
However, many other statements will result in an error, or an exception in Python’s terms:
'3' + 3 # TypeError
---------------------------------------------------------------------------
TypeError Traceback (most recent call last)
Cell In[8], line 1
----> 1 '3' + 3 # TypeError
TypeError: can only concatenate str (not "int") to str
a = [0, 1, 2]
a[3] # IndexError
---------------------------------------------------------------------------
IndexError Traceback (most recent call last)
Cell In[9], line 2
1 a = [0, 1, 2]
----> 2 a[3] # IndexError
IndexError: list index out of range
camel # NameError
---------------------------------------------------------------------------
NameError Traceback (most recent call last)
Cell In[10], line 1
----> 1 camel # NameError
NameError: name 'camel' is not defined
There are many built-in exceptions in Python, and most modules you’ll use created their designated exceptions. Modules and packages do this because the exception is meaningful - each exception conveys information about what went wrong during the runtime. Since it’s not a simple error, we can use this information by predetermining the course of action when an excpetion occurs. This is called catching an exception.
The keywords involved are: try, except, else and finally. An example might consist of interacting with the file system:
try:
# Do something that might fail
file.write()
except PermissionError:
# If we don't have permission to do the operation (e.g. write to protected disk), do the following
# ...
except IsADirectoryError:
# Trying to do a file operation on a directory - so do the following
# ...
except (NameError, TypeError):
# If we encouter either a non-existent variable or operation on variables, do the following
# ...
except Exception:
# General error, not caught by previous exceptions
# ...
else:
# If the operation under "try" succeeded, do the following
# ...
finally:
# Regardless of the result - success or failure - do this.
# ...
Let’s break it down:
# Simplest form of exception handling:
a = 2
try:
b = a + 1
except NameError: # a or b isn't defined
a = 1
b = 2
# We could catch other exceptions
a = '3'
try:
b = a + 1
except TypeError: # a isn't a float\int
a = int(a)
b = a + 1
# With the else clause
current_key = 'Mike'
default_val = 'Cohen'
dict_1 = {'John': 'Doe', 'Jane': 'Doe'}
try:
johns = dict_1.pop(current_key)
except KeyError: # Non-existent key
dict_1[current_key] = default_val
print(f"{len(dict_1)} remaining key(s) in the dictionary")
else:
print(f"{len(dict_1)} remaining key(s) in the dictionary")
print(dict_1)
3 remaining key(s) in the dictionary
{'John': 'Doe', 'Jane': 'Doe', 'Mike': 'Cohen'}
# Another else example
tup = (1,)
try:
a, b = tup[0], tup[1]
except IndexError as e:
print("IndexError")
print(f"Exception: {e}; tup: {tup}")
raise
else:
# process_data(a, b)
print(a, b)
IndexError
Exception: tuple index out of range; tup: (1,)
---------------------------------------------------------------------------
IndexError Traceback (most recent call last)
Cell In[13], line 8
4 a, b = tup[0], tup[1]
5 except IndexError as e:
6 print("IndexError")
7 print(f"Exception: {e}; tup: {tup}")
----> 8 raise
9 else:
10 # process_data(a, b)
11 print(a, b)
IndexError: tuple index out of range
We use the else clause because we wish to catch a specific IndexError during the tuple unpacking (a, b = tup[0], tup[1]). The process_data(a, b) can raise other IndexErrors which we’ll deal with inside the function. But the relevant IndexError to catch is the tuple destructuring one.
# With the finally clause
def divisor(a, b):
"""
Divides two numbers.
a, b - numbers (int, float)
returns a tuple of the result and a possible error.
"""
try:
ans = a / b
except ZeroDivisionError as e:
ans = None
err = e
except TypeError as e:
ans = None
err = e
else:
err = None
# finally:
return ans, err
# Should work:
ans, err = divisor(1, 2)
print(ans, " ----", err)
# ZeroDivisionError:
ans, err = divisor(1, 0)
print(ans, "----", err)
# TypeError
ans, err = divisor(1, 'a')
print(ans, "----", err)
0.5 ---- None
None ---- division by zero
None ---- unsupported operand type(s) for /: 'int' and 'str'
Exception handling is used almost everywhere in the Python world. We always expect our operations to fail, and catch the errors as our backup plan. This is considered more Pythonic than other options. Here’s a “real-world” example:
# Integer conversion. We check before doing it to make sure it won't raise errors
def int_conversion(s):
""" Convert a string to int. """
if not isinstance(s, str) or not s.isdigit():
return None
elif len(s) > 10: # too many digits for int conversion
return None
else:
return int(s)
# Same purpose - more Pythonic
def pythonic_int_conversion(s):
""" Convert a string to int. """
try:
return int(s)
except (TypeError, ValueError, OverflowError):
return None
# This is also sometimes phrased as "easier to ask for forgiveness than permission"
pathlib: A Short Introduction#
For file I/O and other disk operations, some of which are required in this exercise, Pythonistas use pathlib, a module in the Python standard library designated to work with files and folders. It’s a basic premise is that files and folders are objects themselves, and certain operations are allowed between these objects.
from pathlib import Path
p_win = Path(r'C:/Users/Zvi/Documents\Classes\python-course-for-students') # notice the "raw" string r'',
# it forces Python to not duplicate backslashes
p1 = Path('/home/groot/Projects/textbook-public')
p1
PosixPath('/home/groot/Projects/textbook-public')
p1.parent
PosixPath('/home/groot/Projects')
list(p1.parents)
[PosixPath('/home/groot/Projects'),
PosixPath('/home/groot'),
PosixPath('/home'),
PosixPath('/')]
p1.exists() # is it actually a folder\file?
False
p1.parts
('/', 'home', 'groot', 'Projects', 'textbook-public')
p1.name
'textbook-public'
for file in p1.iterdir():
print(file)
---------------------------------------------------------------------------
FileNotFoundError Traceback (most recent call last)
Cell In[26], line 1
----> 1 for file in p1.iterdir():
2 print(file)
File /opt/hostedtoolcache/Python/3.11.15/x64/lib/python3.11/pathlib.py:931, in Path.iterdir(self)
927 def iterdir(self):
928 """Iterate over the files in this directory. Does not yield any
929 result for the special paths '.' and '..'.
930 """
--> 931 for name in os.listdir(self):
932 yield self._make_child_relpath(name)
FileNotFoundError: [Errno 2] No such file or directory: '/home/groot/Projects/textbook-public'
# Traversing the file system
p2 = Path('C:/Users/Zvi/Documents')
p2 / 'Classes' / 'python-course-for-students'
# Operator overloading
PosixPath('C:/Users/Zvi/Documents/Classes/python-course-for-students')
User Input Verification Exercise
The user’s input is always a very error-prone area in an application. A famous joke describes this situation in the following manner:
A Quality Assurance (QA) Engineer walks into a bar. Orders a beer. Orders 0 beers. Orders 999999999 beers. Orders a lizard. Orders -1 beers. Orders a sfdeljknesv.
A decent application should not only handle all possible incoming inputs, but should also convey back to the user the information of what went wrong. In this exercise you’ll write a verify_input function that handles file and folder names:
Assert that the input from a user is a valid folder name. A valid folder is a folder
containing the following files: “a.py”, “b.py”, “c.py”, and the data file “data.txt”. However, the class
should be able to deal with any arbitrary filename, or an iterable of which.
If the given folder doesn’t contain it, it’s possible the user gave us a parent folder of the
folder that contains these Python files. Look into any sub-folders for these files, and return the
“actual” true folder, i.e. the top-most folder containing all the files.
Input - Foldername, string
Output - A pathlib object. If the input isn’t valid, i.e. the files weren’t found,
the class should raise an exception.
Solution
class UserInputVerifier:
"""
Assert that the given foldername contains files in "filenames".
"""
def __init__(self, foldername, filenames=['a.py', 'b.py', 'c.py', 'data.txt']):
self.raw_folder = Path(str(foldername)) # first possible error
self.filenames = self._verify_filenames(filenames)
def _verify_filenames(self, filenames):
""" Verify the input filenames, and return it as an iterable. """
typ = type(filenames)
if typ not in (str, Path, list, tuple, set):
raise TypeError("Filenames should be an iterable, a Path object or a string.")
if typ in (str, Path):
return [filenames]
return filenames
def check_folder(self):
"""
Assert that the files are indeed in the folder or in one of its subfolders.
"""
existing_files = []
missing_files = []
if not self.raw_folder.exists():
raise UserWarning(f"Folder {self.raw_folder} doesn't exist.")
# Recursively look for filenames within folders and sub-folders.
for file_to_look in self.filenames:
found_files = [str(file) for file in self.raw_folder.rglob(file_to_look)]
if len(found_files) == 0:
raise UserWarning(f"File '{file_to_look}' was missing from folder '{self.raw_folder}'.")
if len(found_files) > 1:
raise UserWarning(f"More than one file named '{file_to_look}' was found in '{self.raw_folder}'.")
return True