Class 7b: Tidy format, Visualizations, xarray and Modeling#
Long form (“tidy”) data#
Tidy data was first defined in the R language (its “tidyverse” subset) as the preferred format for analysis and visualization. If you assume that the data you’re about to visualize is always in such a format, you can design plotting libraries that use these assumptions to cut the number of lines of code you have to write in order to see the final art. Tidy data migrated to the Pythonic data science ecosystem, and nowadays it’s the preferred data format in the pandas ecosystem as well. The way to construct a “tidy” table is to follow three simple rules:
Each variable forms a column.
Each observation forms a row.
Each type of observational unit forms a table.
In the paper defining tidy data, the following example is given - Assume we have the following data table:
name |
treatment a |
treatment b |
|---|---|---|
John Smith |
- |
20.1 |
Jane Doe |
15.1 |
13.2 |
Mary Johnson |
22.8 |
27.5 |
Is this the “tidy” form? What are the variables and observations here? Well, we could’ve written this table in a different (‘transposed’) format:
treatment type |
John Smith |
Jane Doe |
Mary Johnson |
|---|---|---|---|
treat. a |
- |
15.1 |
22.8 |
treat. b |
20.1 |
13.2 |
27.5 |
Is this “long form”?
In both cases, the answer is no. We have to move each observation into its own row, and in the above two tables two (or more) observations were placed in the same row. For example, Both observations concerning Mary Johnson (the measured value of treatment a and b) were located in the same row, which violates rule #2 of the “tidy” data rules. This is how the tidy version of the above tables look like:
name |
treatment |
measurement |
|---|---|---|
John Doe |
a |
- |
Jane Doe |
a |
15.1 |
Mary Johnson |
a |
22.8 |
John Doe |
b |
20.1 |
Jane Doe |
b |
13.2 |
Mary Johnson |
b |
27.5 |
Now each measurement has a single row, and the treatment column became an “index” of some sort. The only shortcoming of this approach is the fact that we now have more cells in the table. We had 9 in the previous two versions, but this one has 18. This is quite a jump, but if we’re smart about our data types (categorical data types) then the jump in memory usage wouldn’t become too hard.
As I wrote in the previous class, pandas has methods to transform data into its long form. You’ll usually need to use df.stack() or df.melt() to make it tidy. Let’s try to make our own data tidy:
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
df = pd.read_csv("pew_raw.csv")
df
| religion | 10000 | 20000 | 30000 | 40000 | 50000 | 75000 | |
|---|---|---|---|---|---|---|---|
| 0 | Agnostic | 27 | 34 | 60 | 81 | 76 | 137 |
| 1 | Atheist | 12 | 27 | 37 | 52 | 35 | 70 |
| 2 | Buddhist | 27 | 21 | 30 | 34 | 33 | 58 |
| 3 | Catholic | 418 | 617 | 732 | 670 | 638 | 1116 |
| 4 | Dont know/refused | 15 | 14 | 15 | 11 | 10 | 35 |
| 5 | Evangelical Prot | 575 | 869 | 1064 | 982 | 881 | 1486 |
| 6 | Hindu | 1 | 9 | 7 | 9 | 11 | 34 |
| 7 | Historically Black Prot | 228 | 244 | 236 | 238 | 197 | 223 |
| 8 | Jehovahs Witness | 20 | 27 | 24 | 24 | 21 | 30 |
| 9 | Jewish | 19 | 19 | 25 | 25 | 30 | 95 |
This is a table from the Pew Research Center on the relations between income (in USD) and religion. This dataset is not in a tidy format since the column headers contain information about specific observations (measurements). For example, the 27 agnostic individuals who donated less than $10k represent a measurement, and the 34 that donated $10k-20k represent another one, and so on.
To make it tidy we’ll use melt():
tidy_df = (
pd.melt(df, id_vars=["religion"], var_name="income", value_name="freq")
.sort_values(by="religion")
.reset_index(drop=True)
.astype({"income": "category", "religion": "category"})
)
tidy_df
| religion | income | freq | |
|---|---|---|---|
| 0 | Agnostic | 10000 | 27 |
| 1 | Agnostic | 40000 | 81 |
| 2 | Agnostic | 50000 | 76 |
| 3 | Agnostic | 75000 | 137 |
| 4 | Agnostic | 20000 | 34 |
| 5 | Agnostic | 30000 | 60 |
| 6 | Atheist | 50000 | 35 |
| 7 | Atheist | 30000 | 37 |
| 8 | Atheist | 20000 | 27 |
| 9 | Atheist | 40000 | 52 |
| 10 | Atheist | 10000 | 12 |
| 11 | Atheist | 75000 | 70 |
| 12 | Buddhist | 50000 | 33 |
| 13 | Buddhist | 10000 | 27 |
| 14 | Buddhist | 20000 | 21 |
| 15 | Buddhist | 40000 | 34 |
| 16 | Buddhist | 75000 | 58 |
| 17 | Buddhist | 30000 | 30 |
| 18 | Catholic | 50000 | 638 |
| 19 | Catholic | 40000 | 670 |
| 20 | Catholic | 30000 | 732 |
| 21 | Catholic | 75000 | 1116 |
| 22 | Catholic | 20000 | 617 |
| 23 | Catholic | 10000 | 418 |
| 24 | Dont know/refused | 30000 | 15 |
| 25 | Dont know/refused | 50000 | 10 |
| 26 | Dont know/refused | 10000 | 15 |
| 27 | Dont know/refused | 75000 | 35 |
| 28 | Dont know/refused | 20000 | 14 |
| 29 | Dont know/refused | 40000 | 11 |
| 30 | Evangelical Prot | 30000 | 1064 |
| 31 | Evangelical Prot | 75000 | 1486 |
| 32 | Evangelical Prot | 20000 | 869 |
| 33 | Evangelical Prot | 10000 | 575 |
| 34 | Evangelical Prot | 50000 | 881 |
| 35 | Evangelical Prot | 40000 | 982 |
| 36 | Hindu | 75000 | 34 |
| 37 | Hindu | 30000 | 7 |
| 38 | Hindu | 50000 | 11 |
| 39 | Hindu | 20000 | 9 |
| 40 | Hindu | 40000 | 9 |
| 41 | Hindu | 10000 | 1 |
| 42 | Historically Black Prot | 50000 | 197 |
| 43 | Historically Black Prot | 40000 | 238 |
| 44 | Historically Black Prot | 75000 | 223 |
| 45 | Historically Black Prot | 30000 | 236 |
| 46 | Historically Black Prot | 20000 | 244 |
| 47 | Historically Black Prot | 10000 | 228 |
| 48 | Jehovahs Witness | 10000 | 20 |
| 49 | Jehovahs Witness | 40000 | 24 |
| 50 | Jehovahs Witness | 75000 | 30 |
| 51 | Jehovahs Witness | 50000 | 21 |
| 52 | Jehovahs Witness | 30000 | 24 |
| 53 | Jehovahs Witness | 20000 | 27 |
| 54 | Jewish | 30000 | 25 |
| 55 | Jewish | 40000 | 25 |
| 56 | Jewish | 20000 | 19 |
| 57 | Jewish | 10000 | 19 |
| 58 | Jewish | 50000 | 30 |
| 59 | Jewish | 75000 | 95 |
The first argument to melt is the column name that will be used as the “identifier variable”, i.e. will be repeated as necessary to be used as an “index” of some sorts. var_name is the new name of the column we made from the values in the old columns, and value_name is the name of the column that contains the actual values in the cells from before.
After the melting I sorted the dataframe to make it look prettier (all agnostics in row, etc.) and threw away the old and irrelevant index. Finally I converted the “religion” and “income” columns to a categorical data type, which saves memory and better conveys their true meaning.
Data Visualization#
As mentioned previously the visualization landscape in Python is rich, and is becoming richer by the day. Below, we’ll explore some of the options we have.
* We’ll assume that 2D data is accessed from a dataframe.
matplotlib#
The built-in df.plot() method is a simple wrapper around pyplot from matplotlib, and as we’ve seen before it works quite well for many types of plots, as long as we wish to keep them all overlayed in some sort. Let’s look at examples taken straight from the visualization manual of pandas:
ts = pd.Series(np.random.randn(1000),
index=pd.date_range('1/1/2000', periods=1000))
df = pd.DataFrame(np.random.randn(1000, 4),
index=ts.index,
columns=list('ABCD'))
df = df.cumsum()
df
| A | B | C | D | |
|---|---|---|---|---|
| 2000-01-01 | 0.513079 | -0.623246 | 0.339461 | -1.971483 |
| 2000-01-02 | -1.580696 | -1.436291 | 0.341728 | 0.119157 |
| 2000-01-03 | 1.015075 | -1.835342 | 2.055493 | -0.280817 |
| 2000-01-04 | 1.667443 | -1.726933 | 2.844989 | -1.759204 |
| 2000-01-05 | 2.067496 | -0.380753 | 3.923027 | -1.875805 |
| ... | ... | ... | ... | ... |
| 2002-09-22 | 21.191253 | 25.048046 | 20.771146 | -17.659081 |
| 2002-09-23 | 20.497248 | 22.784478 | 24.330143 | -15.102895 |
| 2002-09-24 | 18.895603 | 22.420286 | 24.854324 | -14.369865 |
| 2002-09-25 | 19.288479 | 22.646016 | 26.096839 | -12.761449 |
| 2002-09-26 | 18.034789 | 23.049526 | 26.653821 | -12.900177 |
1000 rows × 4 columns
_ = df.plot()
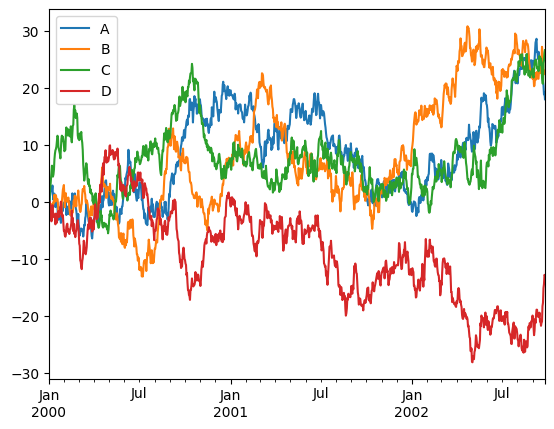
Nice to see we got a few things for “free”, like sane x-axis labels and the legend.
We can tell pandas which column corresponds to x, and which to y:
_ = df.plot(x='A', y='B')
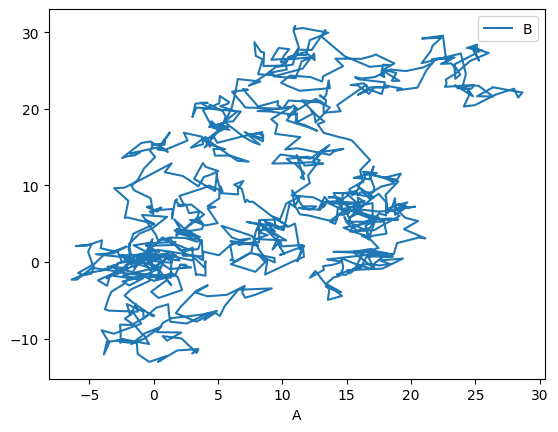
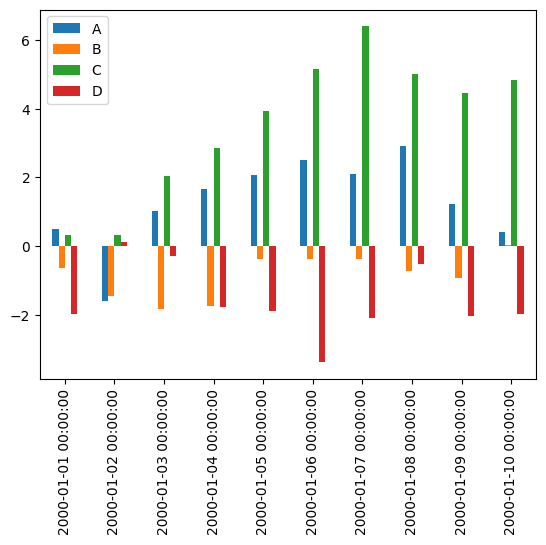
There are, of course, many possible types of plots that can be directly called from the pandas interface:
_ = df.iloc[:10, :].plot.bar()
_ = df.plot.hist(alpha=0.5)
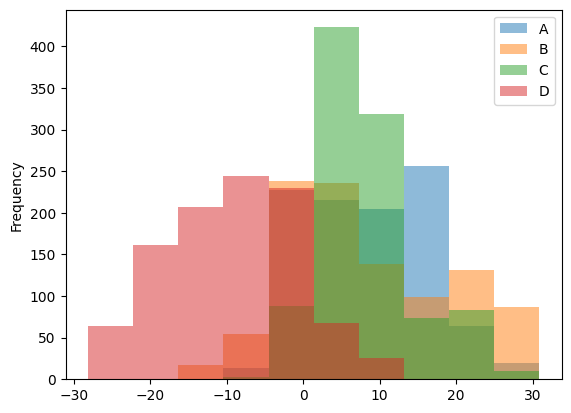
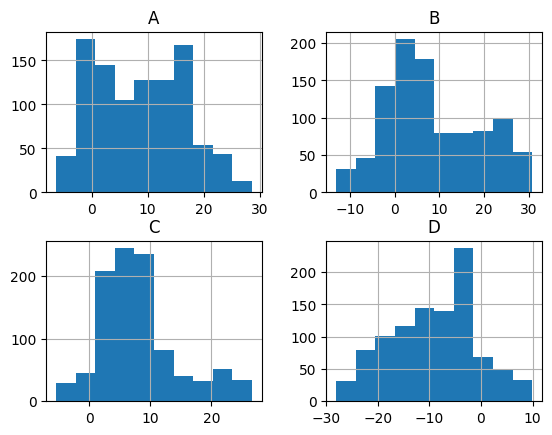
Histogramming each column separately can be done by calling the hist() method directly:
_ = df.hist()
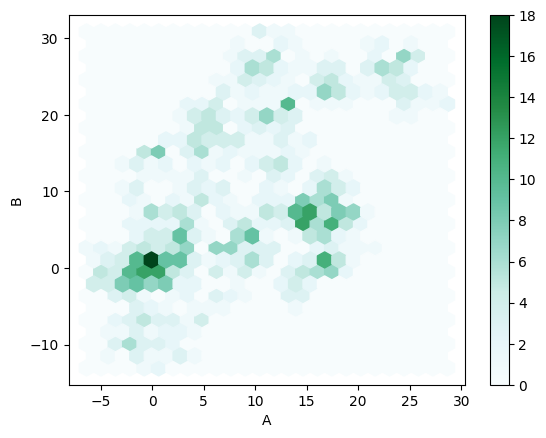
Lastly, a personal favorite:
_ = df.plot.hexbin(x='A', y='B', gridsize=25)
Altair#
Matplotlib (and pandas’ interface to it) is the gold standard in the Python ecosystem - but there are other ecosystems as well. For example, vega-lite is a famous plotting library for the web and Javascript, and it uses a different grammar to define its plots. If you’re familiar with it you’ll be delighted to hear that Python’s altair provides bindings to it, and even if you’ve never heard of it it’s always nice to see that there are many other different ways to tell a computer how to draw stuff on the screen. Let’s look at a couple of examples:
import altair as alt
chart = alt.Chart(df)
chart.mark_point().encode(x='A', y='B')
In Altair you first create a chart object (a simple Chart above), and then you ask it to mark_point(), or mark_line(), to add that type of visualization to the chart. Then we specify the axis and other types of parameters (like color) and map (or encode) them to their corresponding column.
Let’s see how Altair works with other datatypes:
datetime_df = pd.DataFrame({'value': np.random.randn(100).cumsum()},
index=pd.date_range('2020', freq='D', periods=100))
datetime_df.head()
| value | |
|---|---|
| 2020-01-01 | 0.758404 |
| 2020-01-02 | 0.056629 |
| 2020-01-03 | -0.813407 |
| 2020-01-04 | 0.362922 |
| 2020-01-05 | 1.247119 |
chart = alt.Chart(datetime_df.reset_index())
chart.mark_line().encode(x='index:T', y='value:Q')
Above we plot the datetime data by telling Altair that the column named “index” is of type T, i.e. Time, while the column “value” is of type Q for quantitative.
One of the great things about these charts is that they can easily be made to be interactive:
from vega_datasets import data # ready-made DFs for easy visualization examples
cars = data.cars
cars()
| Name | Miles_per_Gallon | Cylinders | Displacement | Horsepower | Weight_in_lbs | Acceleration | Year | Origin | |
|---|---|---|---|---|---|---|---|---|---|
| 0 | chevrolet chevelle malibu | 18.0 | 8 | 307.0 | 130.0 | 3504 | 12.0 | 1970-01-01 | USA |
| 1 | buick skylark 320 | 15.0 | 8 | 350.0 | 165.0 | 3693 | 11.5 | 1970-01-01 | USA |
| 2 | plymouth satellite | 18.0 | 8 | 318.0 | 150.0 | 3436 | 11.0 | 1970-01-01 | USA |
| 3 | amc rebel sst | 16.0 | 8 | 304.0 | 150.0 | 3433 | 12.0 | 1970-01-01 | USA |
| 4 | ford torino | 17.0 | 8 | 302.0 | 140.0 | 3449 | 10.5 | 1970-01-01 | USA |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 401 | ford mustang gl | 27.0 | 4 | 140.0 | 86.0 | 2790 | 15.6 | 1982-01-01 | USA |
| 402 | vw pickup | 44.0 | 4 | 97.0 | 52.0 | 2130 | 24.6 | 1982-01-01 | Europe |
| 403 | dodge rampage | 32.0 | 4 | 135.0 | 84.0 | 2295 | 11.6 | 1982-01-01 | USA |
| 404 | ford ranger | 28.0 | 4 | 120.0 | 79.0 | 2625 | 18.6 | 1982-01-01 | USA |
| 405 | chevy s-10 | 31.0 | 4 | 119.0 | 82.0 | 2720 | 19.4 | 1982-01-01 | USA |
406 rows × 9 columns
cars_url = data.cars.url
cars_url # The data is online and in json format which is standard practice for altair-based workflows
'https://cdn.jsdelivr.net/npm/vega-datasets@v1.29.0/data/cars.json'
alt.Chart(cars_url).mark_point().encode(
x='Miles_per_Gallon:Q',
y='Horsepower:Q',
color='Origin:N', # N for nominal, i.e. discrete and unordered (just like colors)
)
brush = alt.selection_interval() # selection of type 'interval'
alt.Chart(cars_url).mark_point().encode(
x='Miles_per_Gallon:Q',
y='Horsepower:Q',
color='Origin:N', # N for nominal, i.e.discrete and unordered (just like colors)
).add_selection(brush)
/tmp/ipykernel_2587/4283793207.py:5: AltairDeprecationWarning:
Deprecated since `altair=5.0.0`. Use add_params instead.
).add_selection(brush)
The selection looks good but doesn’t do anything. Let’s add functionality:
alt.Chart(cars_url).mark_point().encode(
x='Miles_per_Gallon:Q',
y='Horsepower:Q',
color=alt.condition(brush, 'Origin:N', alt.value('lightgray'))
).add_selection(
brush
)
/tmp/ipykernel_2587/1309016458.py:5: AltairDeprecationWarning:
Deprecated since `altair=5.0.0`. Use add_params instead.
).add_selection(
Altair has a ton more visualization types, some of which are more easily generated than others, and some are easier to generate using Altair rather than Matplotlib.
Bokeh, Holoviews and pandas-bokeh#
Bokeh is another visualization effort in the Python ecosystem, but this time it revolves around web-based plots. Bokeh can be used directly, but it also serves as a backend plotting device for more advanced plotting libraries, like Holoviews and pandas-bokeh. It’s also designed in mind with huge datasets that don’t fit in memory, which is something that other tools might have trouble visualizing.
import bokeh
from bokeh.io import output_notebook, show
from bokeh.plotting import figure as bkfig
output_notebook()
bokeh_figure = bkfig(width=400, height=400)
x = [1, 2, 3, 4, 5]
y = [6, 7, 2, 4, 5]
bokeh_figure.scatter(x,
y,
size=15,
line_color="navy",
fill_color="orange",
fill_alpha=0.5)
show(bokeh_figure)
We see how bokeh immediately outputs an interactive graph, i.e. an HTML document that will open in your browser (a couple of cells above we kindly asked bokeh to output its plots to the notebook instead). Bokeh can be used for many other types of plots, like:
datetime_df = datetime_df.reset_index()
datetime_df
| index | value | |
|---|---|---|
| 0 | 2020-01-01 | 0.758404 |
| 1 | 2020-01-02 | 0.056629 |
| 2 | 2020-01-03 | -0.813407 |
| 3 | 2020-01-04 | 0.362922 |
| 4 | 2020-01-05 | 1.247119 |
| ... | ... | ... |
| 95 | 2020-04-05 | 16.805485 |
| 96 | 2020-04-06 | 16.392804 |
| 97 | 2020-04-07 | 14.924507 |
| 98 | 2020-04-08 | 15.291686 |
| 99 | 2020-04-09 | 15.177724 |
100 rows × 2 columns
bokeh_figure_2 = bkfig(x_axis_type="datetime",
title="Value over Time",
height=350,
width=800)
bokeh_figure_2.xgrid.grid_line_color = None
bokeh_figure_2.ygrid.grid_line_alpha = 0.5
bokeh_figure_2.xaxis.axis_label = 'Time'
bokeh_figure_2.yaxis.axis_label = 'Value'
bokeh_figure_2.line(datetime_df.index, datetime_df.value)
show(bokeh_figure_2)
Let’s look at energy consumption, split by source (from the Pandas-Bokeh manual):
url = "https://raw.githubusercontent.com/PatrikHlobil/Pandas-Bokeh/master/docs/Testdata/energy/energy.csv"
df_energy = pd.read_csv(url, parse_dates=["Year"])
df_energy.head()
| Year | Oil | Gas | Coal | Nuclear Energy | Hydroelectricity | Other Renewable | |
|---|---|---|---|---|---|---|---|
| 0 | 1970-01-01 | 2291.5 | 826.7 | 1467.3 | 17.7 | 265.8 | 5.8 |
| 1 | 1971-01-01 | 2427.7 | 884.8 | 1459.2 | 24.9 | 276.4 | 6.3 |
| 2 | 1972-01-01 | 2613.9 | 933.7 | 1475.7 | 34.1 | 288.9 | 6.8 |
| 3 | 1973-01-01 | 2818.1 | 978.0 | 1519.6 | 45.9 | 292.5 | 7.3 |
| 4 | 1974-01-01 | 2777.3 | 1001.9 | 1520.9 | 59.6 | 321.1 | 7.7 |
Another Bokeh-based library is Holoviews. Its uniqueness stems from the way it handles DataFrames with multiple columns, and the way you add plots to each other. It’s very suitable for Jupyter notebook based plots:
import holoviews as hv
hv.extension("bokeh")


df_energy.head()
| Year | Oil | Gas | Coal | Nuclear Energy | Hydroelectricity | Other Renewable | |
|---|---|---|---|---|---|---|---|
| 0 | 1970-01-01 | 2291.5 | 826.7 | 1467.3 | 17.7 | 265.8 | 5.8 |
| 1 | 1971-01-01 | 2427.7 | 884.8 | 1459.2 | 24.9 | 276.4 | 6.3 |
| 2 | 1972-01-01 | 2613.9 | 933.7 | 1475.7 | 34.1 | 288.9 | 6.8 |
| 3 | 1973-01-01 | 2818.1 | 978.0 | 1519.6 | 45.9 | 292.5 | 7.3 |
| 4 | 1974-01-01 | 2777.3 | 1001.9 | 1520.9 | 59.6 | 321.1 | 7.7 |
scatter = hv.Scatter(df_energy, 'Oil', 'Gas')
scatter
scatter + hv.Curve(df_energy, 'Oil', 'Hydroelectricity')
def get_year_coal(df, year) -> int:
return df.loc[df["Year"] == year, "Coal"]
items = {year: hv.Bars(get_year_coal(df_energy, year)) for year in df_energy["Year"]}
hv.HoloMap(items, kdims=['Year'])
Holoviews really needs an entire class (or two) to go over its concepts, but once you get them you can create complicated visualizations which include a strong interactive component in a few lines of code.
Seaborn#
A library which has really become a shining example of quick, efficient and clear plotting in the post-pandas era is seaborn. It combines many of the features of the previous libraries into a very concise API. Unlike a few of the previous libraries, however, it doesn’t use bokeh as its backend, but matplotlib, which means that the interactivity of the resulting plots isn’t as good. Be that as it may, it’s still a widely used library, and for good reasons.
In order to use seaborn to its full extent (and really all of the above libraries) we have to transform our data into a long-form format.
Once we have this long form data, we can put seaborn to the test.
tidy_df.sample(10)
| religion | income | freq | |
|---|---|---|---|
| 2 | Agnostic | 50000 | 76 |
| 25 | Dont know/refused | 50000 | 10 |
| 18 | Catholic | 50000 | 638 |
| 27 | Dont know/refused | 75000 | 35 |
| 42 | Historically Black Prot | 50000 | 197 |
| 59 | Jewish | 75000 | 95 |
| 39 | Hindu | 20000 | 9 |
| 41 | Hindu | 10000 | 1 |
| 37 | Hindu | 30000 | 7 |
| 47 | Historically Black Prot | 10000 | 228 |
import seaborn as sns
income_barplot = sns.barplot(data=tidy_df, x='income', y='freq', hue='religion')
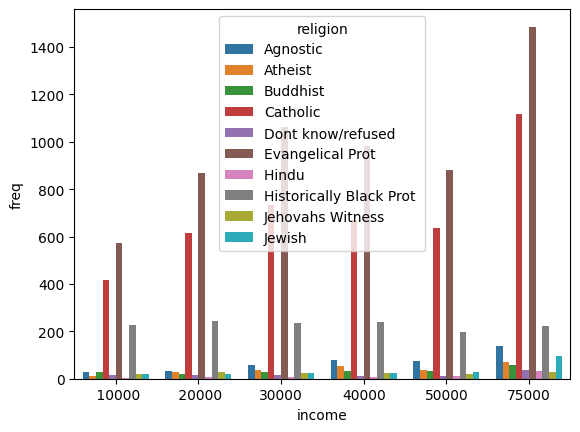
To fix the legend location:
income_barplot = sns.barplot(data=tidy_df, x='income', y='freq', hue='religion')
_ = income_barplot.legend(bbox_to_anchor=(1, 1))
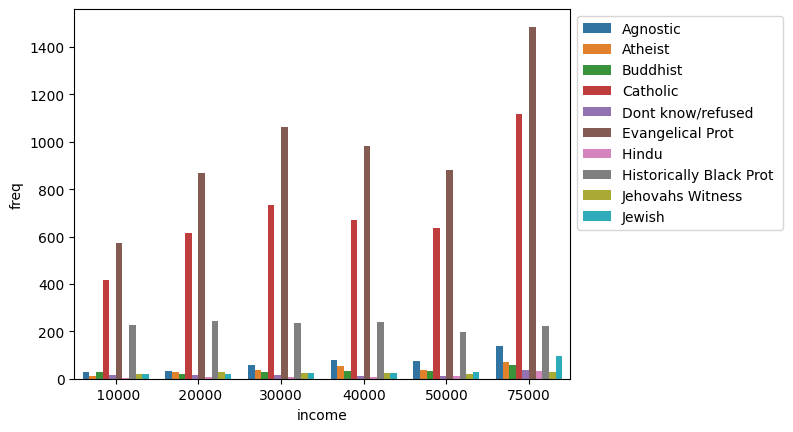
Each seaborn visualization functions has a “data” keyword to which you pass your dataframe, and then a few other with which you specify the relations of the columns to one another. Look how simple it was to receive this beautiful bar chart.
income_catplot = sns.catplot(data=tidy_df, x="religion", y="freq", hue="income", aspect=2)
_ = plt.xticks(rotation=45)
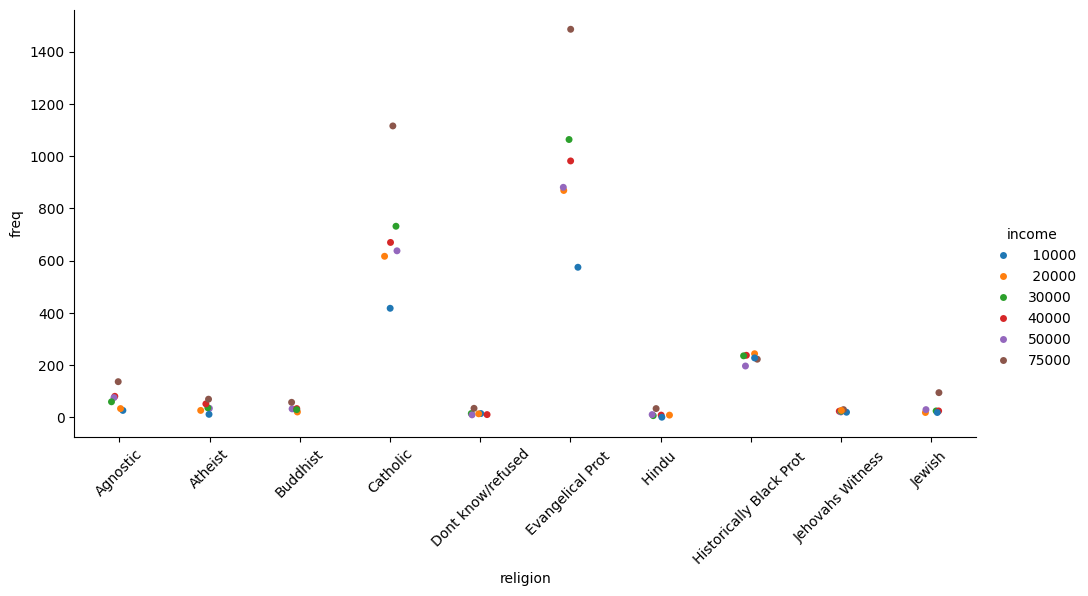
Seaborn also takes care of faceting the data for us:
_ = sns.catplot(data=tidy_df, x="religion", y="freq", hue="income", col="income")

Figure is a bit small? We can use matplotlib to change it:
_, ax = plt.subplots(figsize=(25, 8))
_ = sns.stripplot(data=tidy_df, x="religion", y="freq", hue="income", ax=ax)
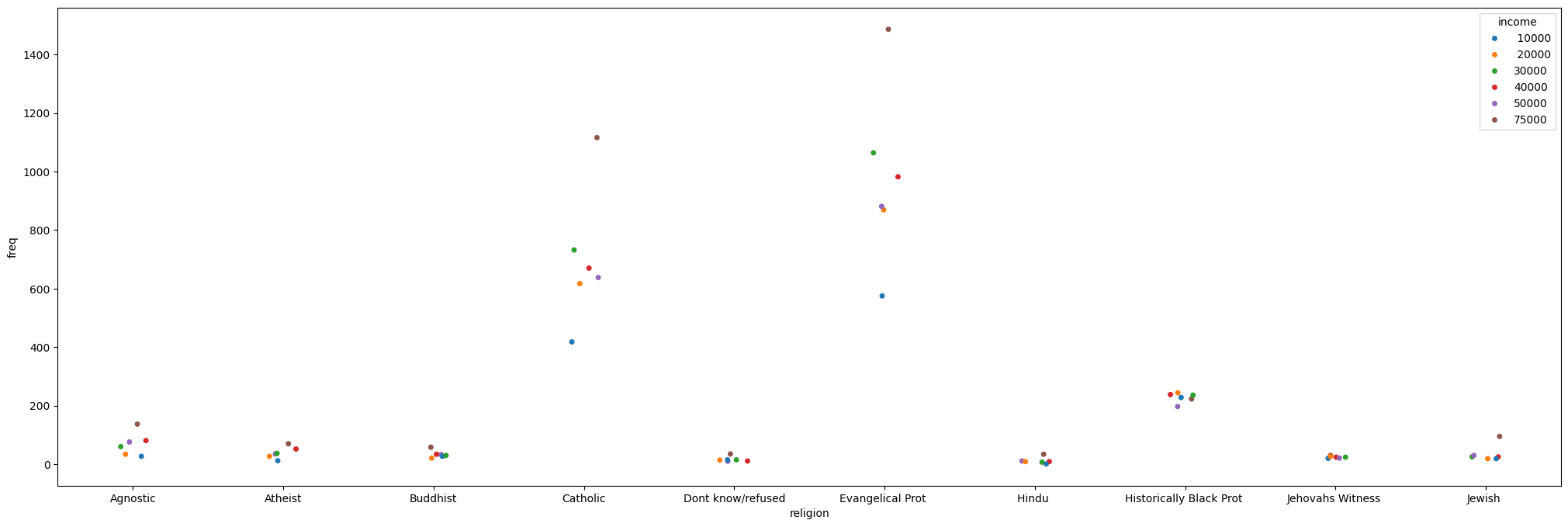
Simpler data can also be visualized, no need for categorical variables:
simple_df = pd.DataFrame(np.random.random((1000, 4)), columns=list('abcd'))
simple_df
| a | b | c | d | |
|---|---|---|---|---|
| 0 | 0.797426 | 0.013355 | 0.808517 | 0.246084 |
| 1 | 0.393164 | 0.235863 | 0.693158 | 0.181890 |
| 2 | 0.701007 | 0.927755 | 0.939201 | 0.126802 |
| 3 | 0.676695 | 0.000394 | 0.814151 | 0.826703 |
| 4 | 0.087560 | 0.270458 | 0.205969 | 0.374860 |
| ... | ... | ... | ... | ... |
| 995 | 0.275213 | 0.701685 | 0.564492 | 0.421276 |
| 996 | 0.795619 | 0.890139 | 0.336636 | 0.307265 |
| 997 | 0.904963 | 0.824001 | 0.134802 | 0.484021 |
| 998 | 0.950055 | 0.876334 | 0.025698 | 0.841324 |
| 999 | 0.027478 | 0.912005 | 0.138282 | 0.276662 |
1000 rows × 4 columns
_ = sns.jointplot(data=simple_df, x='a', y='b', kind='kde')
And complex relations can also be visualized:
_ = sns.pairplot(data=simple_df)
Seaborn should probably be your go-to choice when all you need is a 2D graph.
Higher Dimensionality: xarray#
Pandas is amazing, but has its limits. A DataFrame can be a multi-dimensional container when using a MultiIndex, but it’s limited to a subset of uses in which another layer of indexing makes sense.
In many occasions, however, our data is truly high-dimensional. A simple case could be electro-physiological recordings, or calcium traces. In these cases we have several indices (some can be categorical), like “Sex”, “AnimalID”, “Date”, “TypeOfExperiment” and perhaps a few more. But the data itself is a vector of numbers representing voltage or fluorescence. Having this data in a dataframe seems a bit “off”, what are the columns on this dataframe? Is each column a voltage measurement? Or if each column is a measurement, how do you deal with the indices? We can use nested columns (MultiIndex the columns), but it’s not a very modular approach.
This is a classic example where pandas’ dataframes “fail”, and indeed pandas used to have a higher-dimensionality container named Panel. However, in late 2016 pandas developers deprecated it, publicly announcing that they intend to drop support for Panels sometime in the future, and whoever needs a higher-dimensionality container should use xarray.
xarray is a labeled n-dimensional array. Just like a DataFrame is a labeled 2D array, i.e. with names to its axes rather than numbers, in xarray each dimension has a name (time, temp, voltage) and its indices (“coordinates”) can also have labels (like a timestamp, for example). In addition, each xarray object also has metadata attached to it, in which we can write details that do not fit a columnar structure (experimenter name, hardware and software used for acquisition, etc.).
DataArray#
import numpy as np
import xarray as xr
da = xr.DataArray(np.random.random((10, 2)))
da
<xarray.DataArray (dim_0: 10, dim_1: 2)> Size: 160B
array([[0.31281092, 0.09878567],
[0.55704905, 0.92044519],
[0.35931628, 0.19427105],
[0.50099743, 0.152989 ],
[0.03173841, 0.37182821],
[0.46656681, 0.0552592 ],
[0.62778754, 0.85581477],
[0.87797402, 0.43544303],
[0.83775748, 0.92644252],
[0.62316481, 0.43504288]])
Dimensions without coordinates: dim_0, dim_1The basic building block of xarray is a DataArray, an n-dimensional counter part of a pandas’ Series. It has two dimensions, just like the numpy array that its based upon. We didn’t specify names for these dimensions, so currently they’re called dim_0 and dim_1. We also didn’t specify coordinates (indices), so the printout doesn’t report of any coordinates for the data.
da.values # just like pandas
array([[0.31281092, 0.09878567],
[0.55704905, 0.92044519],
[0.35931628, 0.19427105],
[0.50099743, 0.152989 ],
[0.03173841, 0.37182821],
[0.46656681, 0.0552592 ],
[0.62778754, 0.85581477],
[0.87797402, 0.43544303],
[0.83775748, 0.92644252],
[0.62316481, 0.43504288]])
da.coords
Coordinates:
*empty*
da.dims
('dim_0', 'dim_1')
da.attrs
{}
We’ll add coordinates and dimension names and see how indexing works:
dims = ('time', 'repetition')
coords = {'time': np.linspace(0, 1, num=10),
'repetition': np.arange(2)}
da2 = xr.DataArray(np.random.random((10, 2)), dims=dims, coords=coords)
da2
<xarray.DataArray (time: 10, repetition: 2)> Size: 160B
array([[0.11707941, 0.15312766],
[0.00969727, 0.29113865],
[0.49552188, 0.39200487],
[0.35174594, 0.00243718],
[0.58911128, 0.09252114],
[0.97878958, 0.3660365 ],
[0.39505274, 0.17929093],
[0.55082547, 0.33227346],
[0.9393611 , 0.89694675],
[0.83611317, 0.77391667]])
Coordinates:
* time (time) float64 80B 0.0 0.1111 0.2222 ... 0.7778 0.8889 1.0
* repetition (repetition) int64 16B 0 1da2.loc[0.1:0.3, 1] # rows 1-2 in the second column
<xarray.DataArray (time: 2)> Size: 16B
array([0.29113865, 0.39200487])
Coordinates:
* time (time) float64 16B 0.1111 0.2222
repetition int64 8B 1da2.isel(time=slice(3, 7)) # dimension name and integer label (sel = select)
<xarray.DataArray (time: 4, repetition: 2)> Size: 64B
array([[0.35174594, 0.00243718],
[0.58911128, 0.09252114],
[0.97878958, 0.3660365 ],
[0.39505274, 0.17929093]])
Coordinates:
* time (time) float64 32B 0.3333 0.4444 0.5556 0.6667
* repetition (repetition) int64 16B 0 1da2.sel(time=slice(0.1, 0.3), repetition=[1]) # dimension name and coordinate label
<xarray.DataArray (time: 2, repetition: 1)> Size: 16B
array([[0.29113865],
[0.39200487]])
Coordinates:
* time (time) float64 16B 0.1111 0.2222
* repetition (repetition) int64 8B 1Other operations on DataArray instances, such as computations, grouping and such, are done very similarly to dataframes and numpy arrays.
Dataset#
A Dataset is to a DataArray what a DataFrame is to a Series. In other words, it’s a collection of DataArray instances that share coordinates.
da2 # a reminder. We notice that this could've been a DataFrame as well
<xarray.DataArray (time: 10, repetition: 2)> Size: 160B
array([[0.11707941, 0.15312766],
[0.00969727, 0.29113865],
[0.49552188, 0.39200487],
[0.35174594, 0.00243718],
[0.58911128, 0.09252114],
[0.97878958, 0.3660365 ],
[0.39505274, 0.17929093],
[0.55082547, 0.33227346],
[0.9393611 , 0.89694675],
[0.83611317, 0.77391667]])
Coordinates:
* time (time) float64 80B 0.0 0.1111 0.2222 ... 0.7778 0.8889 1.0
* repetition (repetition) int64 16B 0 1ds = xr.Dataset({'ephys': da2,
'calcium': ('time', np.random.random(10))},
attrs={'AnimalD': 701,
'ExperimentType': 'double',
'Sex': 'Male'})
ds
<xarray.Dataset> Size: 336B
Dimensions: (time: 10, repetition: 2)
Coordinates:
* time (time) float64 80B 0.0 0.1111 0.2222 ... 0.7778 0.8889 1.0
* repetition (repetition) int64 16B 0 1
Data variables:
ephys (time, repetition) float64 160B 0.1171 0.1531 ... 0.8361 0.7739
calcium (time) float64 80B 0.2278 0.3302 0.4925 ... 0.08253 0.3288
Attributes:
AnimalD: 701
ExperimentType: double
Sex: Maleds['ephys'] # individual DataArrays can be dissimilar in shape
<xarray.DataArray 'ephys' (time: 10, repetition: 2)> Size: 160B
array([[0.11707941, 0.15312766],
[0.00969727, 0.29113865],
[0.49552188, 0.39200487],
[0.35174594, 0.00243718],
[0.58911128, 0.09252114],
[0.97878958, 0.3660365 ],
[0.39505274, 0.17929093],
[0.55082547, 0.33227346],
[0.9393611 , 0.89694675],
[0.83611317, 0.77391667]])
Coordinates:
* time (time) float64 80B 0.0 0.1111 0.2222 ... 0.7778 0.8889 1.0
* repetition (repetition) int64 16B 0 1Exercise: Rat Visual Stimulus Experiment Database#
You’re measuring the potential of neurons in a rat’s brain over time in response to flashes of light using a multi-electrode array surgically inserted into the rat’s skull. Each trial is two seconds long, and one second into the trial a short, 100 ms, bright light is flashed at the animal. After 30 seconds the experiment is replicated, for a total of 4 repetitions. The relevant parameters are the following:
Rat ID.
Experimenter name.
Rat gender.
Measured voltage (10 electrode, 10k samples representing two seconds).
Stimulus index (mark differently the pre-, during- and post-stimulus time).
Repetition number.
Mock data and model it, you can add more parameters if you feel so.
Experimental timeline:
1s 100ms 0.9s 30s
Start -----> Flash -----> End flash -----> End trial -----> New trial
| |
|--------------------------------------------------------------------|
x4
Methods and functions to implement#
There should be a class holding this data table,
VisualStimData, alongside several methods for the analysis of the data. The class should have adataattribute containing the data table, in axarray.DataArrayor axarray.Dataset.Write a function (not a method) that returns an instance of the class with mock data.
def mock_stim_data() -> VisualStimData: """ Creates a new VisualStimData instance with mock data """
When simulating the recorded voltage, it’s completely fine to not model spikes precisely, with leaky integration and so forth - randoming numbers and treating them as the recorded neural potential is fine. There are quite a few ways to model real neurons, if so you wish, brian being one of them. If your own research will benefit from knowing how to use these tools, this exercise is a great place to start familiarizing yourself with them.
Write a method that receives a repetition number, rat ID, and a list of electrode numbers, and plots the voltage recorded from these electrodes. The single figure should be divided into however many plots needed, depending on the length of the list of electrode numbers.
def plot_electrode(self, rep_number: int, rat_id: int, elec_number: tuple=(0,)): """ Plots the voltage of the electrodes in "elec_number" for the rat "rat_id" in the repetition "rep_number". Shows a single figure with subplots. """
To see if the different experimenters influence the measurements, write a method that calculates the mean, standard deviation and median of the average voltage trace across all repetitions, for each experimenter, and shows a bar plot of it.
def experimenter_bias(self): """ Shows the statistics of the average recording across all experimenters """
Exercise solutions below…#
---------------------------------------------------------------------------
ValueError Traceback (most recent call last)
File pandas/_libs/tslibs/offsets.pyx:6343, in pandas._libs.tslibs.offsets.to_offset()
ValueError: invalid literal for int() with base 10: '0.0002'
During handling of the above exception, another exception occurred:
ValueError Traceback (most recent call last)
Cell In[54], line 2
1 # Run the solution
----> 2 stim_data = mock_stim_data()
3 ids = stim_data.data['rat_id']
4 arr = stim_data.plot_electrode(rep_number=2, rat_id=ids[0], elec_number=(1, 6))
Cell In[53], line 13, in mock_stim_data()
11 experimenters = _generate_experimenter_names(num_of_animals, num_of_reps)
12 rat_sex = _generate_rat_gender(num_of_animals, num_of_reps)
---> 13 stim, electrode_array, time, volt = _generate_voltage_stim(num_of_animals, num_of_reps)
15 # Construct the Dataset - this could be done with a pd.MultiIndex as well
16 ds = xr.Dataset({'temp': (['num'], room_temp),
17 'humid': (['num'], room_humid),
18 'volt': (['elec', 'time', 'rat_id', 'rep'], volt),
(...) 26 'num': exp_number,
27 })
Cell In[53], line 72, in _generate_voltage_stim(num_of_animals, num_of_reps)
69 volt = 0.02 * np.random.randn(electrodes, samples, num_of_animals,
70 num_of_reps).astype(np.float32) - 0.068 # in volts, not millivolts
71 volt[volt > -0.02] = 0.04 # "spikes"
---> 72 time = pd.date_range(start=pd.to_datetime('today'), periods=experiment_length * sampling_rate,
73 freq=f'{freq}S')
74 electrode_array = np.arange(electrodes, dtype=np.uint16)
76 # Stim index - -1 is pre, 0 is stim, 1 is post
File /opt/hostedtoolcache/Python/3.11.15/x64/lib/python3.11/site-packages/pandas/core/indexes/datetimes.py:1442, in date_range(start, end, periods, freq, tz, normalize, name, inclusive, unit, **kwargs)
1440 freq = "D"
1441 if freq is not None:
-> 1442 freq = to_offset(freq)
1444 if start is NaT or end is NaT:
1445 # This check needs to come before the `unit = start.unit` line below
1446 raise ValueError("Neither `start` nor `end` can be NaT")
File pandas/_libs/tslibs/offsets.pyx:6229, in pandas._libs.tslibs.offsets.to_offset()
File pandas/_libs/tslibs/offsets.pyx:6352, in pandas._libs.tslibs.offsets.to_offset()
File pandas/_libs/tslibs/offsets.pyx:6137, in pandas._libs.tslibs.offsets.raise_invalid_freq()
ValueError: Invalid frequency: 0.0002S. Failed to parse with error message: ValueError("invalid literal for int() with base 10: '0.0002'")
---------------------------------------------------------------------------
NameError Traceback (most recent call last)
Cell In[55], line 1
----> 1 stim_data.data
NameError: name 'stim_data' is not defined